
「新人エンジニアにおすすめの書籍」としてよく挙げられる、「ネットワークはなぜつながるのか」の要点を図を用いて分かりやすくまとめてみました。
「本当は本を読みたいけど面倒で。。」という方の助けになれば幸いです。
では始めます。
「ネットワークはなぜつながるのか」の要点を分かりやすくまとめてみた
ブラウザにURLを入力してから画面が表示されるまでの流れは以下の通りです。
- 入力されたURLを解釈する
- HTTPリクエストメッセージを作成する
- DNSにサーバーのIPアドレスを問い合わせる
- プロトコル・スタックにリクエストメッセージの送信を依頼する
- 送信されたデータがネットワーク上を進む
- ファイアウォール、キャッシュ・サーバー、負荷分散装置などを通過する
- サーバーがレスポンスデータを返す
- レスポンスを受け取ってWebサイトの画面を表示する
- サーバーとクライアントの接続を切断する
それぞれ説明していきます。
1. 入力されたURLを解釈する
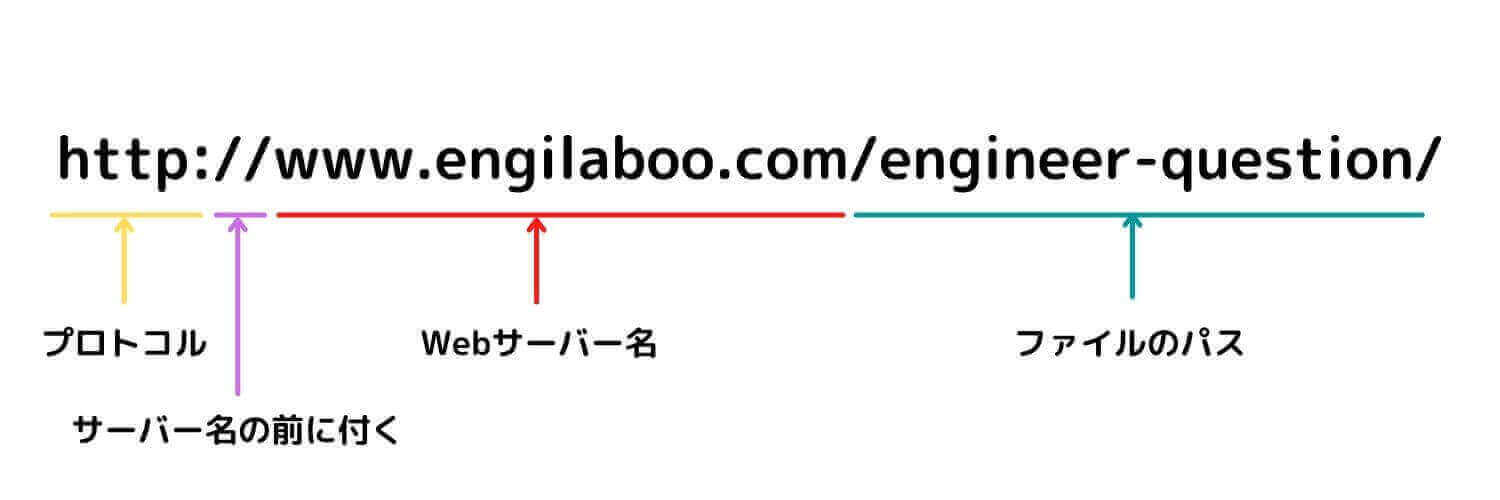
ブラウザにURLが入力されたら、ブラウザがURLを「解釈」します。
具体的には、以下のようにURLの中身を分解し、「どのプロトコルで」「どのWebサーバーの」「どのパスに」アクセスするかを洗い出します。
2. HTTPリクエストメッセージを作成する
ブラウザが、URLから解釈した情報を基に「HTTPリクエストメッセージ」を作成します。
HTTPリクエストメッセージは以下のような形式になっています。

リクエスト・ラインには、リクエストメッセージのメインとなる情報(メソッド・URI・HTTPバージョン)を記載します。
メッセージ・ヘッダーにはリクエストの付加情報を記載します。
メッセージ・ボディには、クライアントからサーバーに送るデータを記述します。
GETリクエストの場合は何も入りません。
3. DNSにサーバーのIPアドレスを問い合わせる
ブラウザは、Socketライブラリのリゾルバを使ってDNSサーバーにドメイン名を問い合わせ、サーバーの「IPアドレス」を取得します。
なぜなら、OSにメッセージの送信を依頼するときには、サーバーの「ドメイン名」ではなく、「IPアドレス」で宛先を指定する必要があるからです。
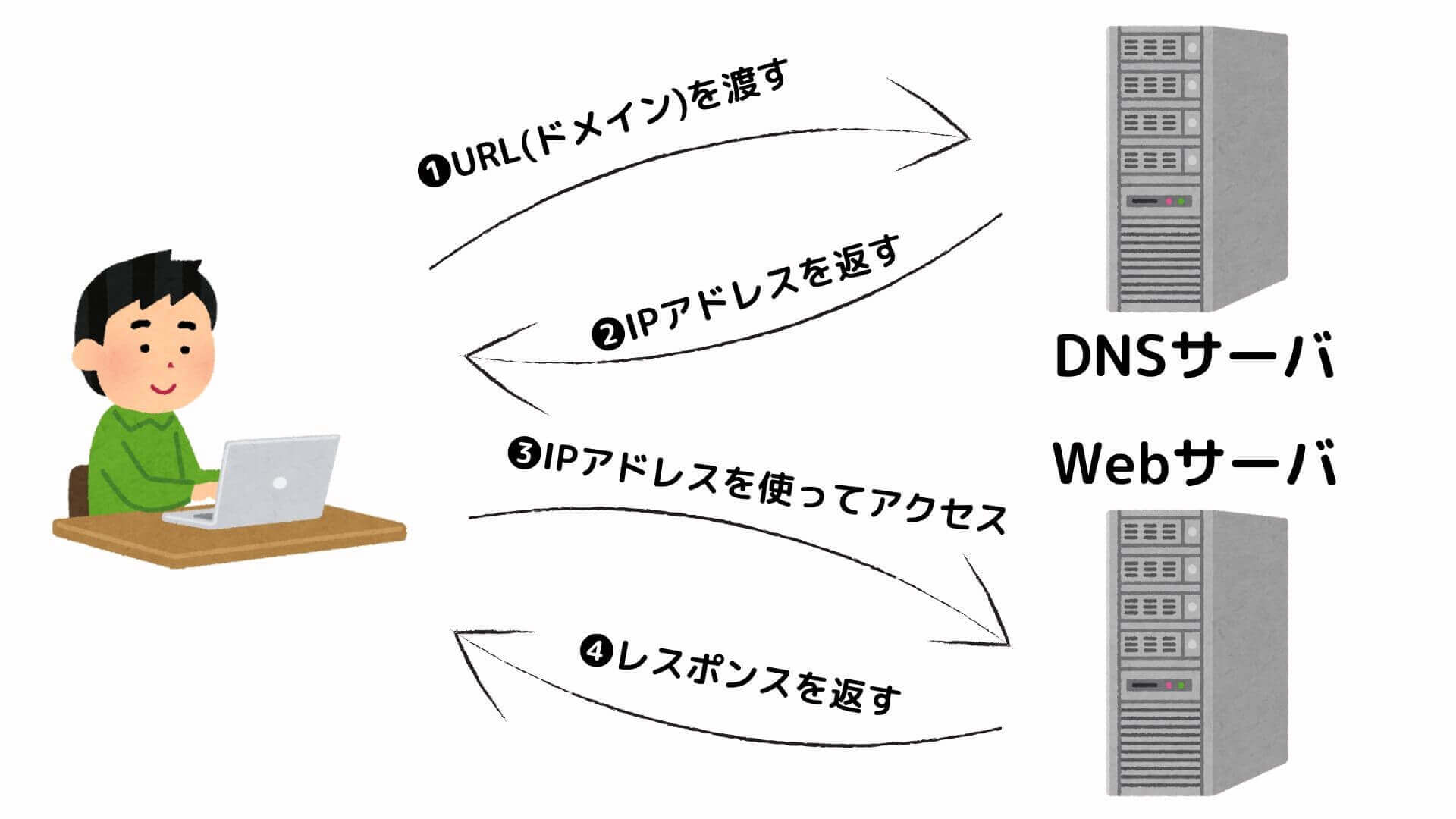
このように、DNSからIPアドレスを取得することを「ネーム・リゾリューション(名前解決)」と言います。
こうして取得したIPアドレスは、ブラウザが指定したメモリに保存されます。
そしてブラウザがサーバーに対してリクエストを送る際には、このメモリからIPアドレスを取り出し、HTTPリクエストメッセージと共にOSに送信を依頼します。

hostsファイルについて知りたい方はこちらの記事を読んでみてください
4. プロトコル・スタックにリクエストメッセージの送信を依頼する
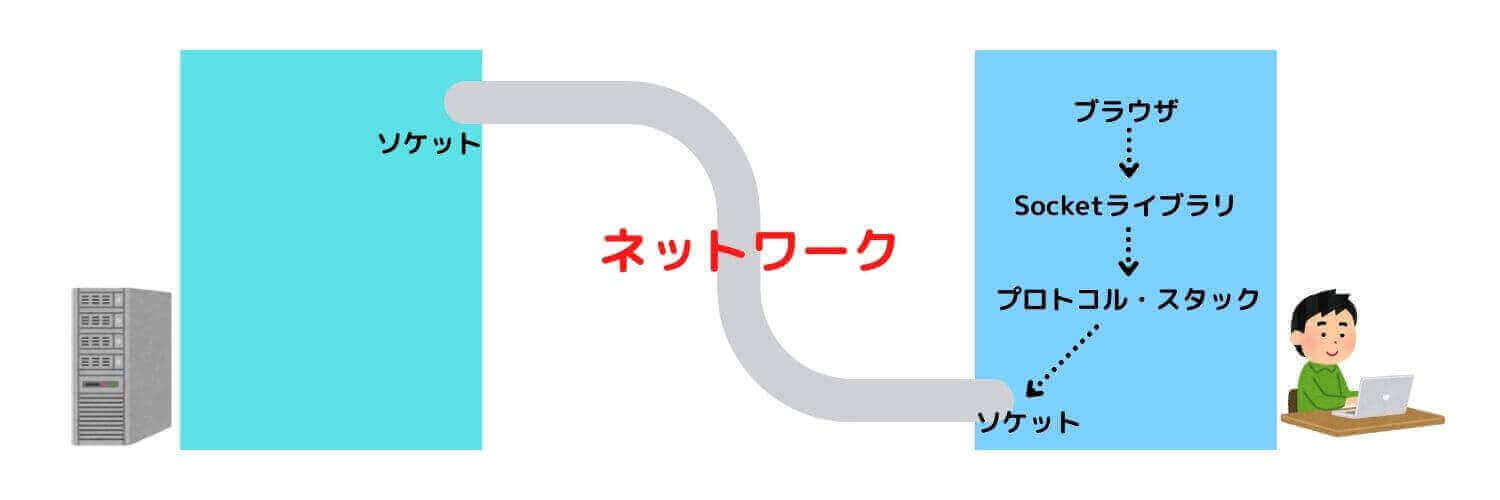
IPが分かったら、ブラウザはプロトコル・スタック(OS内部に組み込まれたネットワーク制御用ソフトウェア)にリクエストメッセージの送信を依頼します。
より細かく言うと、ブラウザはリクエストメッセージを送信するにあたり、Socketライブラリ内の各種プログラム部品を呼び出して以下の3つの手順を実行し、必要に応じてプロトコル・スタックを介してサーバーとやり取りを行います。
- ソケットの作成
- サーバー側のソケットにパイプを接続
- リクエストメッセージの送信
ソケットとは、サーバー・クライアント間でやり取りするデータの「出入り口」のことです。
ソケットは、Socketライブラリのsocketというプログラムを呼び出すことで作成されます。
作成されると、「ディスクリプタ」というものが渡されます。これは各アプリが自分が使用するソケットを識別するために使われます。
次に、サーバー側のソケットにパイプを接続します。
この動作は、Socketライブラリのconnectというプログラムを呼び出すことで実行されます。
このconnectを呼び出す際には、「ソケットのディスクリプタ」「サーバーのIPアドレス」「ポート番号」が渡されます。
そして、connectはこれらの情報をプロトコル・スタックに通知します。
これらの情報は、プロトコル・スタックでそれぞれ以下の目的のために使われます。
- ソケットのディスクリプタ・・・どのソケットを使ってサーバーと通信するかを判断するため
- サーバーのIPアドレス・・・どのサーバーと通信するかを判断するため
- サーバーのポート番号・・・サーバー内のどのソケットと通信するかを判断するため
これらの情報が分かれば、プロトコル・スタックは実際にサーバーとの接続を実行します。
そして、相手と繋がり次第、サーバーのIPやポートをソケットに記録します。
これにより、サーバーとHTTPリクエスト(レスポンス)メッセージのやり取りが可能な状態となります。
あとはサーバーにリクエストメッセージを送るだけです。
具体的には、ブラウザ(アプリケーション)がSocketライブラリのwriteというプログラムを介してプロトコル・スタックにメッセージの送信を依頼します。
依頼を受けたプロトコル・スタックは、先ほど作成したパイプ(ネットワーク)を介してサーバーにHTTPリクエストメッセージを送信します。
5. 送信されたデータがネットワーク上を進む
クライアントから送信されたデータ(パケット)がネットワーク上を進んでいきます。
このときデータは、ハブやルーターなどを経由します。
また、ルーターを出たデータはプロバイダ等を経由して最終的にはサーバー側に到達します。
このようにネットワーク上をデータが進む上で最も避けなければならないのは、「データが途中で損失すること」です。
そのため、「データを損失しないための様々な工夫」が各所でなされています。
この辺りは長くなってしまうので当記事では省略します。
興味のある方は本を読んでみて下さい。
6. ファイアウォール、キャッシュ・サーバー、負荷分散装置などを通過する
サーバーに到達する手前で、データはファイアウォール、キャッシュ・サーバー、負荷分散装置などを通過します。
ファイアウォールとは、いわば関所のようなものです。
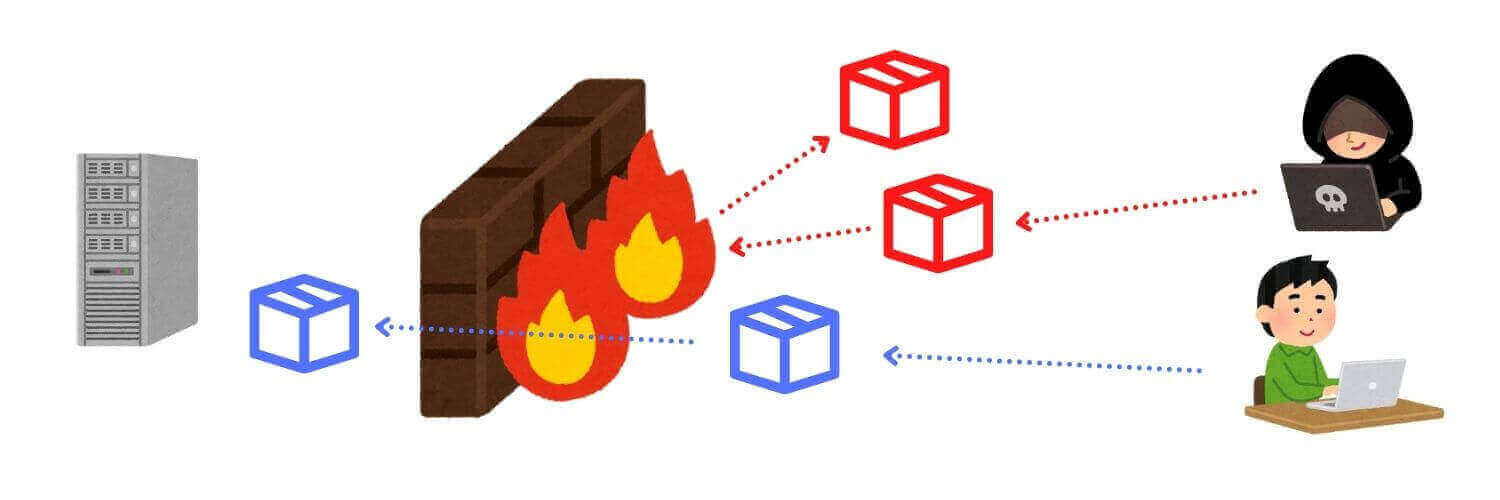
特定のサーバー上で動作する特定のアプリに対するデータ(パケット)のみ許可し、それ以外は跳ね返します。(パケット・フィルタリング)
これにより、サーバーの安全性を高めることができます。
ファイアウォールを通過したデータは、「サーバーの負荷を軽減するための装置」を経由します。
なぜサーバーの負荷を軽減する必要があるのか。
それは、もしアクセスが増えてサーバーの負荷(CPUやメモリ)が上がってしまったら、サーバーがダウンしてしまう可能性があるからです。
サーバーがダウンしてしまったら、サービスを提供できません。
それはサービスを提供してお金を稼いでいる人にとっては絶対に避けたい事態です。
では、どのようにしてサーバーの負荷を軽減するのでしょうか。
もちろん様々な方法がありますが、代表的なのは以下の二つです。
- 負荷分散装置(ロードバランサー)
- キャッシュ・サーバー
負荷分散装置(ロードバランサー)とは、サーバーに対する「負荷」を軽減するための装置です。
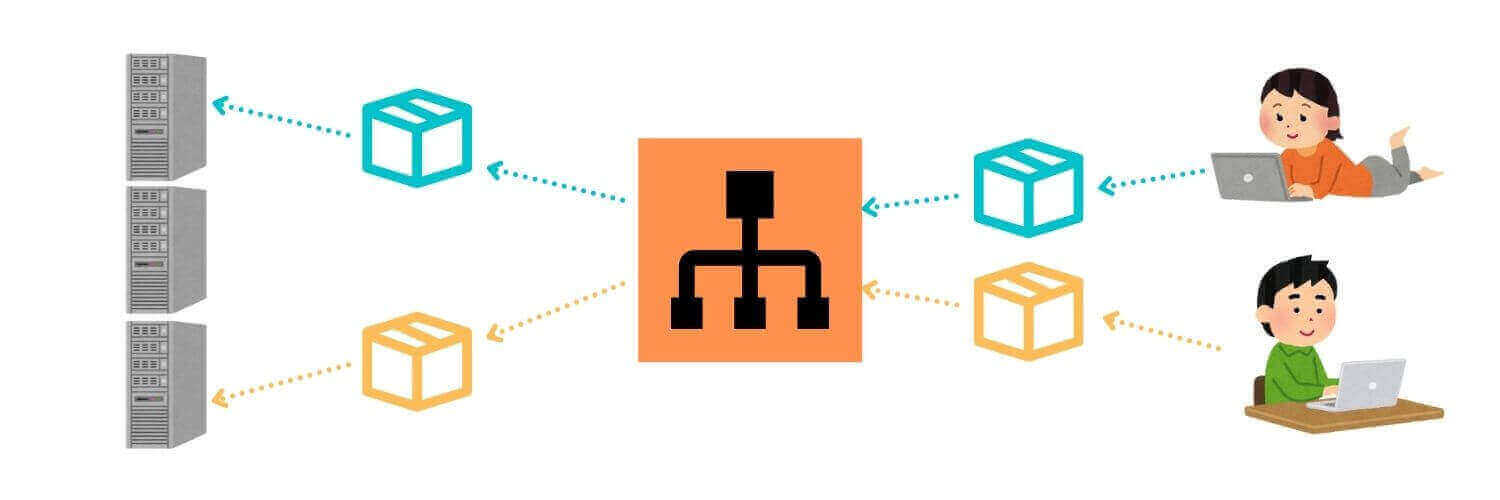
具体的には、複数台のWebサーバーを配置しておき、その手前に負荷分散装置を置きます。
そして負荷分散装置は、特定の方式(ラウンドロビン方式などが有名)に従って各Webサーバーにリクエストを振り分けます。
これにより、一台のWebサーバーにかかる負荷を軽減することができるのです。
キャッシュ・サーバーとは、クライアントに対してキャッシュデータを返すサーバーです。
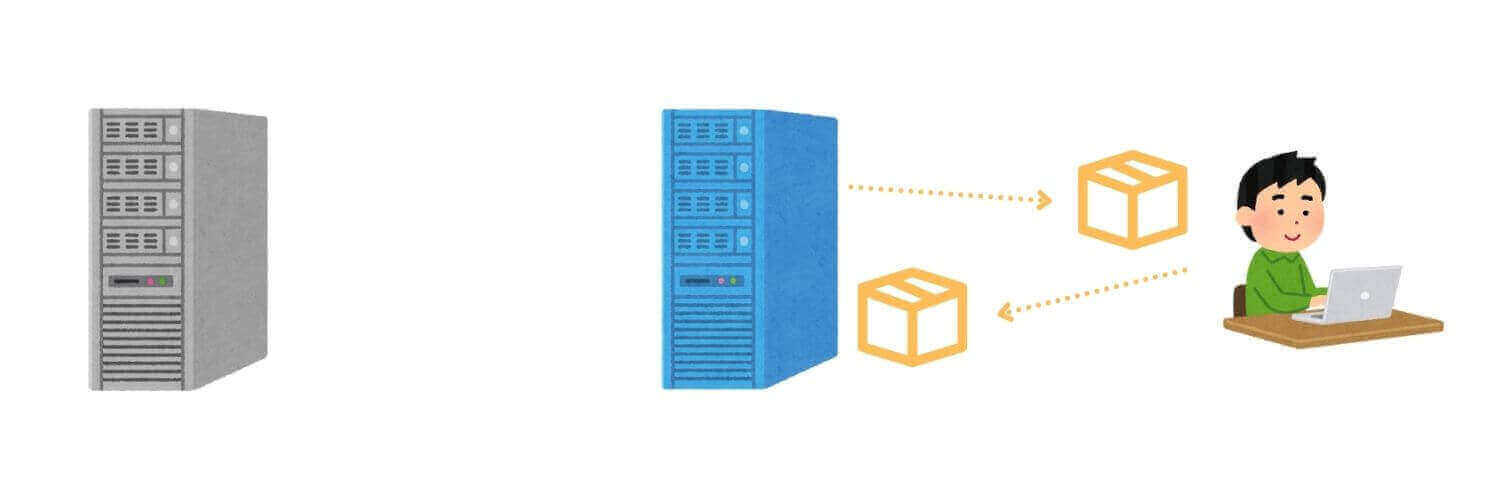
具体的には、以下の流れで処理が実行されます。
- クライアントがサーバーにリクエストを送る
- サーバーがレスポンスを返す
- キャッシュ・サーバーがレスポンスデータを保存(キャッシュ)する
- 再度ユーザーが同じページのリクエストを送る
- サーバーに到達する手前でキャッシュ・サーバーがレスポンスデータを返す
これにより、Webサーバーに対するリクエスト数が減るため、結果的にサーバー負荷を軽減することができるのです。
また、それだけでなく、サーバーまで到達させないことでレスポンス速度が向上するため、ユーザーにも良い影響を与えることができます。
ただ、もちろんずっとキャッシュデータを返していてはコンテンツが更新された際に困るため、キャッシュは一定時間経ったら削除する設定にしている場合が多いと思います。
7. サーバーがレスポンスデータを返す
サーバーまでリクエストが到達したら、サーバーはレスポンスデータを生成してクライアントに返却します。
これは以下の流れで行われます。
- ソケットの作成
- ソケットを待ち受け状態にする
- 接続を受け付ける
- データを返す
ソケットを作る部分はクライアントと同じですが、「接続を待つ」点がクライアントとは違います。
まず、Socketライブラリのbindというプログラムを呼び出して、ソケットにポート番号を記録します。
クライアントはこのポート番号を指定します。
次に、Socketライブラリのlistenを呼び出して、ソケットに「接続待ち」の状態であることを示す制御情報を付与します。
これでソケットは待ち受け状態になります。
待ち受け状態になったら、Socketライブラリのacceptを呼び出して接続を受け付けます。
あとはソケットを経由して受け取った処理をサーバーサイドで処理して、再度ソケットを経由してクライアントに返すだけです。
帰りも行きと同じようにプロバイダーやルーターを経由して、クライアントにレスポンスが到達します。
8. レスポンスを受け取ってWebサイトの画面を表示する
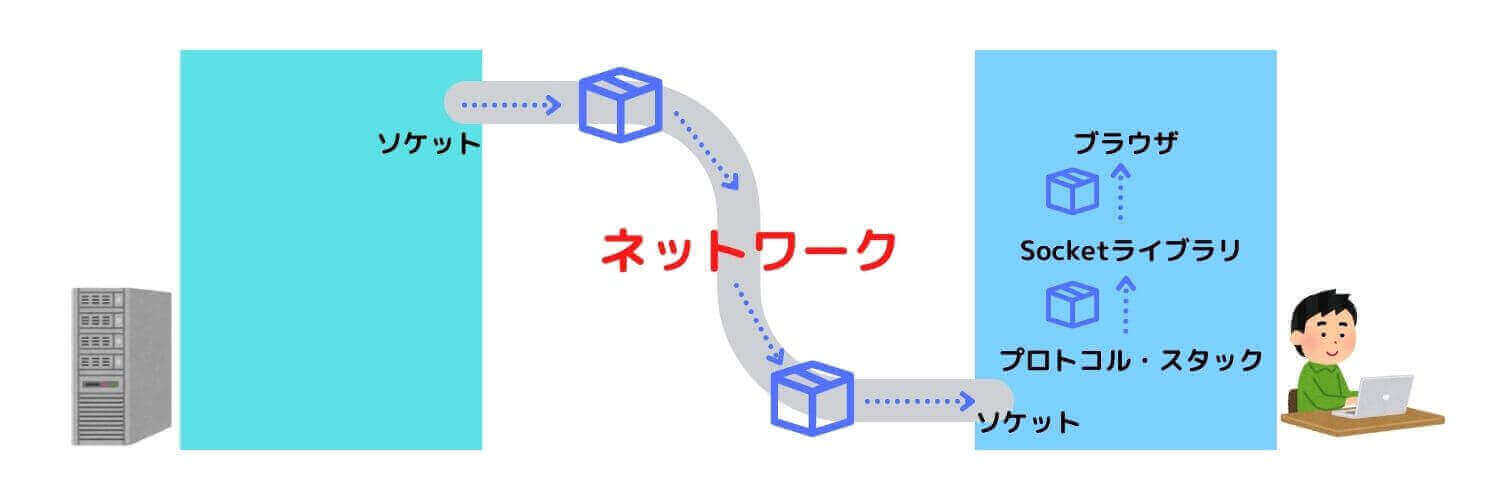
クライアントは、Socketライブラリのreadというプログラムを使用してプロトコル・スタックにデータの受信を依頼します。
このとき、アプリケーション・プログラム内部に、受信データを保存するためのメモリ領域を確保します。
これを「受信バッファ」と呼びます。
実際にデータが届いたら、この「受信バッファ」に保存されたデータを基にブラウザはWebページを表示します。

9. サーバーとクライアントの接続を切断する
最後に後片付けをします。
ブラウザはSocketライブラリのcloseというプログラムを呼び出して、接続の切断フェーズに入るよう依頼します。
これにより、クライアント・サーバー間のパイプが外され、ソケットも消されます。
以上が「ブラウザにURLを入力してからWebページが表示されるまで」の全体像です。
「ネットワークはなぜつながるのか」の要点を分かりやすくまとめてみた おわりに
今回は、「ネットワークはなぜつながるのか」の要点を自分なりにまとめてみました。
少しでもネットワークについて理解を深める上での助けになっていれば幸いです。
また、この記事を読んでより深く内容を知りたいと思った方は実際の書籍も買ってみてください。
ネットワークの全体像が掴める名著なので、手元に一冊置いておいて確実に損はないと思います。
最後まで読んで頂きありがとうございました。

ネットワーク その他のおすすめ本
「ネットワークはなぜつながるのか」に加えて、「ネットワークの重要用語解説」もネットワークを理解する上でオススメです。

ネットワークはなぜつながるのかとは違って、ネットワークの用語を解説している本なのですが、図がとても分かりやすいので理解がしやすいです。
「ネットワークはなぜつながるのか」を読みつつ、分からない用語やより深くしたい用語をネットワークの重要用語解説で補填すれば、よりネットワークに対する理解が深まることでしょう。













